



Integra tu servidor de IA local en LibreNMS
Montar un servidor de IA local puede ser emocionante para todo perfil TIC. Tenerlo corriendo y no saber lo que está haciendo por dentro, no tanto.
El problema de casi todos los setups domésticos de IA es que el servidor existe en un limbo, Ollama responde, los modelos cargan, y el resto es fe ciega. No sabes si la GPU lleva veinte minutos al 95% de temperatura, si Ollama se cayó a las tres de la mañana y lleva horas sin responder, o si el disco donde guardas los modelos está al 90% de capacidad. Te enteras cuando algo ya ha ido mal.
LibreNMS resuelve exactamente eso, y si ya lo tienes corriendo en un Docker, la mitad del trabajo está hecha. Lo que queda es conectar ambos extremos, enseñarle a LibreNMS a hablar con el servidor Ubuntu vía SNMP, exponerle las métricas de la GPU a través de scripts, y configurar un servicio de check HTTP que vigile que el endpoint de Ollama está vivo. El resultado es un dashboard con histórico real, alertas automáticas a Telegram, y visibilidad completa sobre lo que hace tu nodo de IA cada cinco minutos, sin scripts caseros ni cronjobs que nadie mira.
Esta guía asume que tienes el servidor ya configurado y LibreNMS en marcha. No necesitas nada más que acceso SSH al servidor y unos diez minutos.
Instalar y configurar snmpd en Ubuntu
SNMP es el protocolo que usa LibreNMS para consultar el estado del servidor. "snmpd" es el demonio que expone esa información en el servidor Ubuntu. La configuración por defecto es demasiado restrictiva y expone poca información, así que la reemplazamos con una versión optimizada para LibreNMS.
Lanzamos la instalación y realizamos un backup del fichero de configuración original:
sudo apt install -y snmpd snmp libsnmp-dev# Hacer backup de la config original
sudo cp /etc/snmp/snmpd.conf /etc/snmp/snmpd.conf.bak
Reemplaza el contenido de "/etc/snmp/snmpd.conf" con esta configuración limpia:
# ── Comunidad SNMP v2c ──────────────────────────────────────
# Cambia 'librenms' por tu community string realrocommunity librenms 127.0.0.1
rocommunity librenms IP_SERV_LIBRENMS
# ── Información del sistema ─────────────────────────────────
syslocation "Servidor IA Local - Fractal Terra"
syscontact "librenms@pronectic.geeknetic.es"sysName ailab-fractal
# ── Escuchar en todas las interfaces ────────────────────────
agentAddress udp:161,udp6:[::1]:161
# ── Métricas extendidas ─────────────────────────────────────
extend-sh nvidia-gpu /etc/snmp/extend/nvidia-gpu.sh
extend-sh ollama-status /etc/snmp/extend/ollama-status.sh
# ── Acceso a disco, red, CPU completos ──────────────────────
view systemview included .1
access notConfigGroup "" any noauth exact systemview none nonedisk / 10%
disk /opt 10%# ── Procesos a vigilar ──────────────────────────────────────
proc ollama 1proc dockerd 1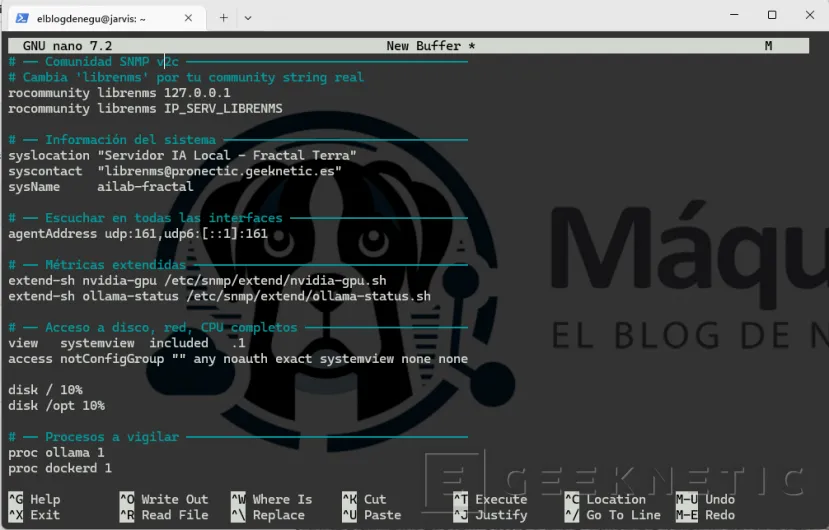
Habilitamos una carpeta para los scripts extendidos, y levantamos / validamos el servicio:
# Crear directorio para los scripts extendsudo mkdir -p /etc/snmp/extend
# Activar y arrancar snmpdsudo systemctl enable --now snmpd
sudo systemctl status snmpd# Verificar que escucha en el puerto 161
sudo ss -ulnp | grep 161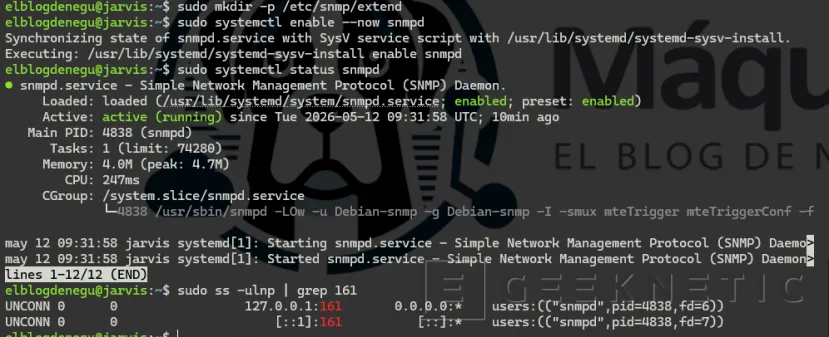
Script Extend: Métricas GPU NVIDIA
Los extend scripts son la forma que tiene LibreNMS de recoger métricas personalizadas vía SNMP. El servidor ejecuta el script localmente y expone el resultado como un OID SNMP que LibreNMS consulta en cada poll. Así integramos la GPU sin necesidad de configuraciones adicionales.
Desde Configuración -> Applications, podemos activar soporte para Docker, NVidia y Systemd, por ejemplo. Una vez habilitadas podréis ver datos en "APPS":
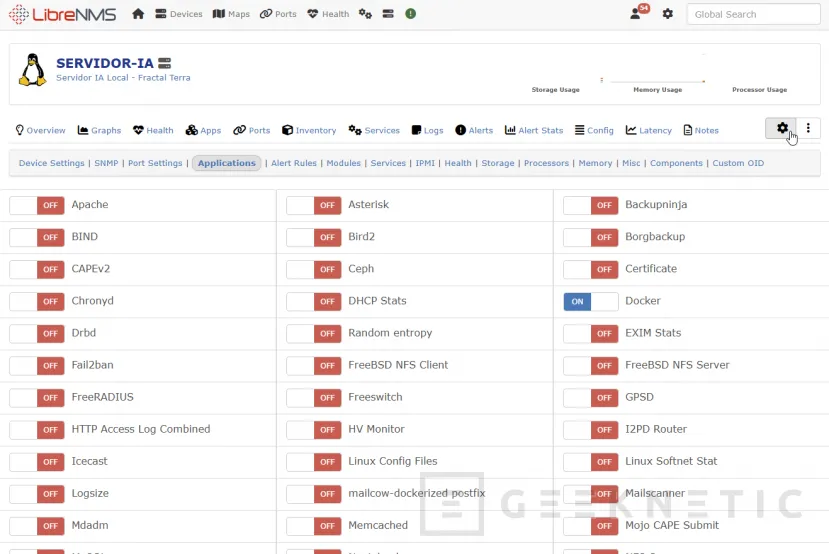
Adicionalmente, podéis crear scripts extends. Os paso dos ejemplos:
Creamos un fichero "sudo nano /etc/snmp/extend/nvidia-gpu.sh" o directamente con el siguiente comando y este contenido:
elblogdenegu@jarvis:~$ sudo tee /etc/snmp/extend/nvidia-gpu.sh > /dev/null << 'SCRIPT'
#!/bin/bash
GPU_TEMP=$(nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader,nounits 2>/dev/null | head -1)
GPU_UTIL=$(nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader,nounits 2>/dev/null | head -1)
GPU_MEM_USED=$(nvidia-smi --query-gpu=memory.used --format=csv,noheader,nounits 2>/dev/null | head -1)
GPU_MEM_TOTAL=$(nvidia-smi --query-gpu=memory.total --format=csv,noheader,nounits 2>/dev/null | head -1)
GPU_POWER=$(nvidia-smi --query-gpu=power.draw --format=csv,noheader,nounits 2>/dev/null | head -1 | xargs printf "%.0f")
GPU_FAN=$(nvidia-smi --query-gpu=fan.speed --format=csv,noheader,nounits 2>/dev/null | head -1)
GPU_NAME=$(nvidia-smi --query-gpu=name --format=csv,noheader 2>/dev/null | head -1)
echo "gpu_name: ${GPU_NAME}"echo "gpu_temp: ${GPU_TEMP}"
echo "gpu_util: ${GPU_UTIL}"echo "vram_used_mib: ${GPU_MEM_USED}"
echo "vram_total_mib: ${GPU_MEM_TOTAL}"echo "power_draw_w: ${GPU_POWER}"
echo "fan_speed_pct: ${GPU_FAN}"SCRIPT
Y otro para Ollama "sudo nano /etc/snmp/extend/ollama-status.sh":
elblogdenegu@jarvis:~$ sudo tee /etc/snmp/extend/ollama-status.sh > /dev/null << 'SCRIPT'
#!/bin/bashOLLAMA_ACTIVE=$(systemctl is-active ollama 2>/dev/null)
OLLAMA_STATUS=0[ "$OLLAMA_ACTIVE" = "active" ] && OLLAMA_STATUS=1
MODELS=$(ollama list 2>/dev/null | tail -n +2 | wc -l)API_OK=0
HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" --max-time 3 http://localhost:11434/api/tags)
[ "$HTTP_CODE" = "200" ] && API_OK=1
echo "ollama_service: ${OLLAMA_STATUS}"echo "ollama_api: ${API_OK}"
echo "models_loaded: ${MODELS}"SCRIPT
Les damos permisos de ejecución y los probamos:
sudo chmod +x /etc/snmp/extend/nvidia-gpu.sh
sudo chmod +x /etc/snmp/extend/ollama-status.sh# Probar los scripts directamente
sudo /etc/snmp/extend/nvidia-gpu.shsudo /etc/snmp/extend/ollama-status.sh
# Reiniciar snmpd para cargar los extendssudo systemctl restart snmpd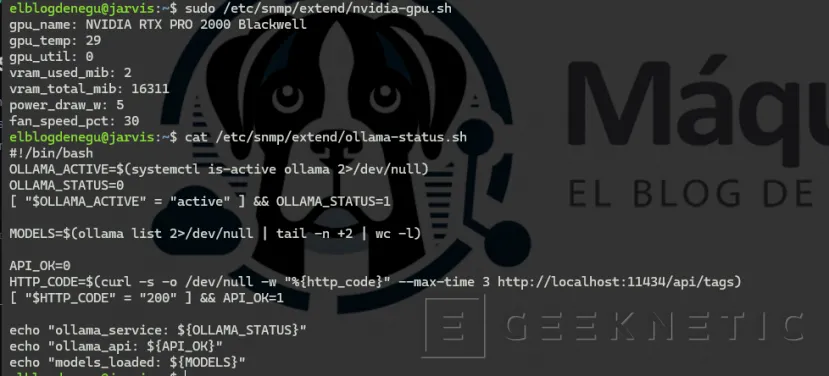
Añadir el servidor como dispositivo en LibreNMS
Con snmpd corriendo en el servidor Ubuntu, ya puedes añadirlo desde la interfaz de LibreNMS. Hay dos formas, por la UI web o por CLI dentro del contenedor Docker. La UI es más cómoda para empezar.
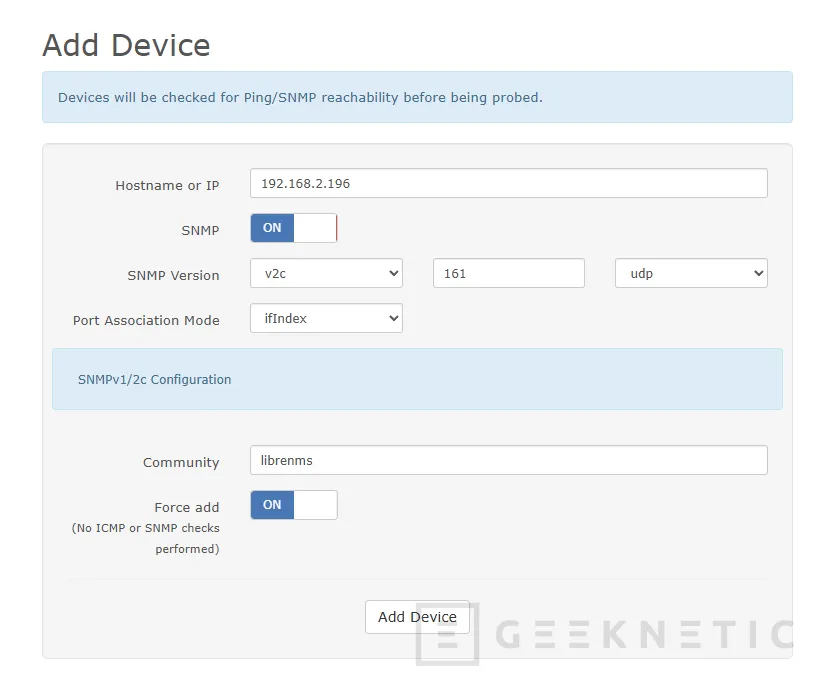
En LibreNMS ve a Devices → Add Device y rellena:
| Campo | Valor |
|---|---|
| Hostname / IP | IP del servidor Ubuntu en tu red local |
| SNMP Version | v2c |
| Community | librenms (la que pusiste en snmpd.conf) |
| Port | 161 |
| Transport | UDP |
| OS | Se detecta automáticamente |
Haz clic en Add Device. LibreNMS lanzará un discovery inmediato. En 2-3 minutos el dispositivo aparecerá con interfaces de red, CPU, memoria y disco ya detectados.
Service check HTTP para el endpoint de Ollama
Además de SNMP, LibreNMS puede hacer service checks estilo Nagios para verificar que un servicio concreto responde. Lo usamos para monitorizar el endpoint HTTP de Ollama de forma independiente al estado del systemd.
En LibreNMS ve al dispositivo que acabas de añadir Services → Add Service:

Rellenamos los datos y pulsamos Add Service:
| Campo | Valor |
|---|---|
| Name | OLLAMA API |
| Device | SERVIDOR-IA (que hemos introducido) |
| Check type | http |
| Description | Comprueba que el endpoint de Ollama responde |
| Remote Host | IP del servidor IA (Ubuntu Server) |
| Parameters | -p 11434 -u /api/tags -e 200 |
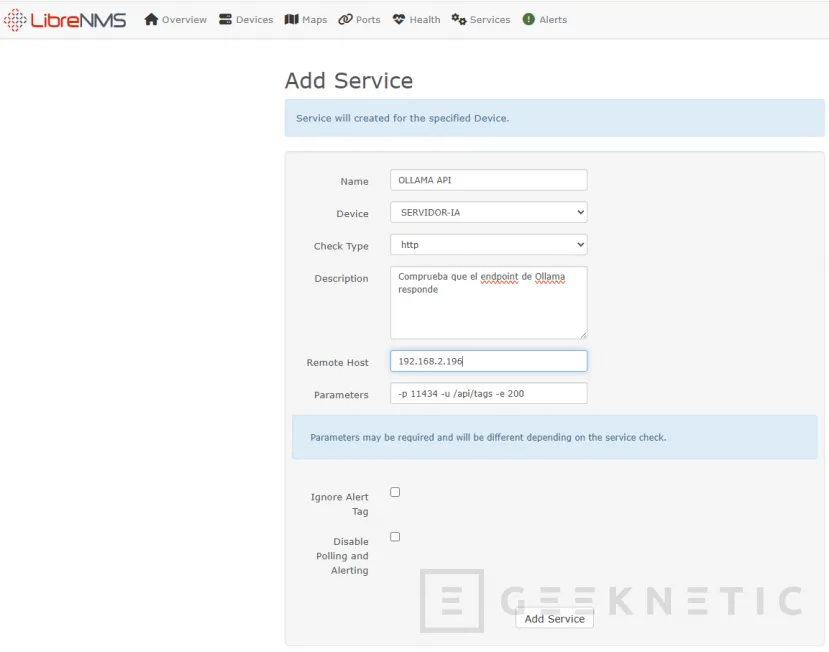
Con "-e 200" le estás diciendo que espera un HTTP 200. Si Ollama cae o no responde en el timeout, el service check pasa a estado CRITICAL y LibreNMS dispara las alertas configuradas.
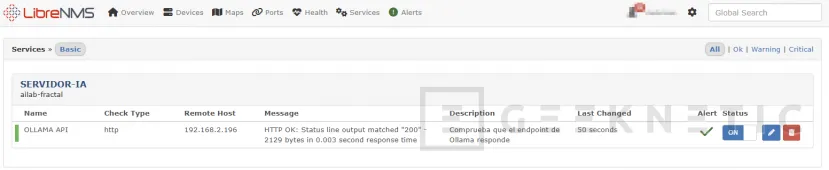
Monitoriza tu servidor de IA
Con esto ya no estás volando a ciegas. LibreNMS sabe cuánta VRAM está usando la RTX Pro 2000 en cada momento, si Ollama responde o no, y cuándo la temperatura empieza a subir más de la cuenta. El histórico RRD te va a resultar útil más pronto de lo que crees, la primera vez que un modelo se quede cargado en memoria sin que te des cuenta y te preguntes por qué el resto de peticiones van lentas, la gráfica de VRAM te lo va a decir de un vistazo.
Lo interesante de esta integración es que escala sin esfuerzo. Si en algún momento añades un segundo servidor, otro nodo con distinta GPU, o empiezas a correr contenedores con modelos especializados, LibreNMS los absorbe exactamente igual, un dispositivo más, los mismos extend scripts, las mismas reglas de alerta. No tienes que repensar nada.
El siguiente paso lógico es llevar estas métricas un poco más lejos, cruzar el uso de VRAM de LibreNMS con los logs de Ollama para saber qué modelos se cargan más, cuánto tiempo se quedan en memoria, y si merece la pena ajustar OLLAMA_KEEP_ALIVE para tu patrón de uso real.
Todo esto con notificaciones de Telegram, Email...hacen que tu servidor de IA local, sea un punto clave en tu infraestructura.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







